Chapter 3: Network Data¶
Managing networks requires gathering information that can be used to drive decisions about how to adapt to changing conditions. Doing so requires gathering information that can be used as input to the decision-making process, which includes models that perform prediction and inference about the state of the network and the applications running on it. This process, often referred to as data acquisition in machine learning, has a longstanding tradition in networking, and is often referred to as simply network measurement. There are many ways to gather information about the network, which we will discuss in this chapter. Ultimately, however, gathering data with the intent of providing input to machine learning models can be a more involved process, since the data must be collected in a way that both results in effective training for the models, and in an efficient manner.
There are many reasons to measure networks and many ways of gathering these measurements. As we discussed in the previous chapter, for example, networks can be measured to for performance diagnosis and troubleshooting, security, forecasting, and many other use cases. Before we can talk about models, we first need to discuss the different ways that network data can be collected. Internet measurement itself is rapidly evolving, as new tools and capabilities emerge. In this chapter, we will explore both conventional techniques for Internet measurement, as well as emerging techniques to measure and gather data from networks. We will also explore how emerging technologies are both expanding the types of measurements that can be gathered from networks and making it possible to gather new types of measurements. We will also talk about the process of transforming the raw data into a form that can be used for training machine learning models—in other words, going from raw measurement data to aggregate statistics and ultimately to features.
We will explore network measurement in the context of two different types of measurement: (1) active measurement, which introduces new traffic into the network to measure various network properties (from performance to topology); and (2) passive measurement, which captures existing traffic on the network to infer information about traffic that is already being sent across the network by existing applications and services. Each of these types of measurements have various classes of tools to measure certain properties, as well as various considerations. A simple way to think about these two classes of measurement is that active measurements can directly measure certain properties of a specific network path (e.g., its capacity, latency, application properties in some cases, or even the path itself) but cannot provide direct insight into the circumstances that a particular user or application may be experiencing.
We’ll then explore these two types of measurement in more detail, explaining how each technique works, and what it can (and cannot) measure. Along the way, we’ll dive into the details with a few examples and hands-on activities, introducing both techniques for processing raw network data into more aggregate statistics, as well as software libraries that can perform some of these transformations. Before getting into specific measurement techniques, let’s talk a little bit about what metrics can be measured in the first place.
Types of Network Data¶
There are a wide variety of metrics that can be measured from network data. We highlight some of the common metrics below. Typically, these metrics can be measured directly, either by injecting traffic into the network and observing behavior (active measurement) or by collecting existing network traffic and computing statistics about what is being observed (passive measurement).
Of course, in machine learning, the goal is inference, which means that the metrics that can be measured directly, which we discuss below, are often used as inputs (or “features”) to a machine learning model to predict or infer higher-level phenomena or events, from application quality of experience to attacks. Below, we highlight some of these metrics, and discuss which of these metrics can be measured with active measurement, passive measurement, or both.
Throughput concerns the amount of time it takes to transfer a certain quantity of data. It is typically measured in bits per second (or some multiple of bits per second, such as gigabits per second). Measuring throughput is important because it indicates how much data a network is capable of moving between two network endpoints within a fixed time window. When networks delivered relatively low throughput, it was the predominant determining factor for a user’s experience. As a result, it is the dimension of performance that is most commonly referred to and benchmarked against when considering things like the performance of consumer broadband Internet access. For example, you might buy a “1 Gigabit” service plan from your ISP, which typically indicates that you can expect a downstream (i.e., from a server somewhere on the Internet to your home) throughput of approximately 1 gigabit per second (1 Gbps).
Latency concerns the amount of time it takes a unit of data (e.g., a packet) to reach an Internet destination. Latency is measured in seconds. A fundamental contributor to latency is the speed of light, but because Internet traffic is multiplexed in queues, when traffic congestion occurs, packets in buffers can also introduce additional latency. Latency is becoming increasingly important, and can be a differentiator in performance between networks, particularly for networks that have network equipment with large buffers that can introduce delays when those parts of the network become bottlenecks. The metric is also becoming increasingly important and relevant in the context of interactive applications, such as video conferencing, gaming, and even the web. A related important metric is latency under load, which is the latency experienced by packets when the network is carrying other traffic that saturates the capacity of the link, even if briefly (e.g., starting a streaming video, uploading a photo, sending an email, browsing the web).
Jitter reflects the change in latency over time—it is effectively the first derivative of latency, or the change in packet inter-arrival time. As with latency, it is measured in seconds (or, more commonly, milliseconds). Many applications, especially interactive ones like voice, video, and gaming, expect network traffic to arrive at regular, fixed intervals. When traffic does not arrive at such fixed intervals either user experience is degraded, or the application must introduce a larger buffer to smooth out variation in packet inter-arrival.
Packet loss concerns the fraction of packets that fail to reach their intended destination. Packet loss can be detrimental to performance because certain transport protocols like the Transmission Control Protocol (TCP) interpret loss as congestion and slow down as a result of observing packet loss. Packet loss is of course also inherently detrimental to user experience, as lost packets represent lost data—which could correspond to frames in a video, words in a voice call, and so forth.
Data Collection Strategies¶
All machine learning pipelines begin with the collection of relevant data. Data can come from many different sources and can vary wildly in complexity. Most importantly, the data you gather, and how you represent it through collections of features, should accurately represent the underlying phenomena you are trying to model. Machine learning algorithms learn primarily through inductive reasoning, i.e., they learn general rules by observing specific instances. If the specific instances in your data are not adequately representative of the general phenomenon you are trying to model, the ML algorithm will not be able to learn the right general rules and any predictions based on the model are less likely to be correct. Thus, decisions about what data to acquire and how to acquire it can often be critical to whether a model is accurate in practice, as well as whether the model is efficient and robust enough to be deployed in practice.
In this respect, domain knowledge is particularly important in the context of machine learning. For example, knowing how patterns of malicious web requests as part of a denial of service attack or vulnerability scan would exhibit different characteristics from legitimate web requests is essential for thinking about the types of features that may ultimately be good for the models you ultimately train. More generally, when designing machine learning pipelines for specific tasks, domain knowledge about the problem you are trying to model can increase the likelihood that the model you design could work well in practice.
When beginning a ML pipeline, it is common to ask, “how much data is necessary to achieve high-quality results?” Unfortunately, answering this question is not straightforward, as it depends the phenomenon you are trying to model, the machine learning algorithm you select, and the quality of the data you are able to gather. Conceptually, you will need to collect enough data such that all of the relevant variability in the underlying phenomenon is represented in the data.
From the perspective of model accuracy, identifying features of the traffic that are likely to result in accurate predictions often requires knowledge of the underlying phenomena; from the perspective of practical deployment, considerations for data acquisition can also go beyond accuracy, because some features are more costly or cumbersome than others. For example, packet traces may contain significantly more information that statistical summaries of network traffic, yet packet traces are orders of magnitude larger, resulting in higher capture overhead, larger memory and storage costs, longer model training time, and so forth. On the other hand, summary statistics are more efficient to collect and store, and could reduce training time, yet they may obscure certain features or characteristics which could ultimately degrade model accuracy. Determining which feature subsets strike the appropriate balance between model accuracy and systems-related modeling costs is a general practical challenge, and the best ways to optimize for this tradeoff remains an open problem.
There are two primary ways to measure networks: active measurement and passive measurement. Active measurement involves injecting traffic into the network and observing the behavior of the network. Passive measurement involves capturing existing traffic on the network and observing the behavior of the network. In this section, we will discuss the two types of measurement in more detail, and explore the different ways that each type of measurement can be used to gather data.
Active Measurement¶
One way to measure the characteristics of a network is to send traffic across the network towards a particular endpoint and observe the characteristics of those measurements in terms of the metrics that we discussed in the previous section. Specifically, one can measure throughput, latency, jitter, packet loss, and other properties of a specific Internet path by sending traffic across the network and observing these metrics of the traffic along that path.
Active measurement is a broad topic: It refers to any type of measurement that involves sending traffic into the network—sometimes referred to as “probes”—and observing how different network endpoints respond to these probes. As far as gathering network traffic data is concerned, active measurements involve various tradeoffs. On one hand, conducting active measurements does not typically involve privacy considerations, since it does not involve capturing user traffic that may include sensitive information (e.g., the websites that a user is visiting). Additionally, because active measurements can be run from any network endpoint, they are typically easier to gather than passive measurements (which can often require the installation of specific passive network traffic capture infrastructure).
There are many different types of active measurements one could perform, and as a result, there are simply too many types to cover in this chapter. We will, however, have a brief look at three types of active Internet measurements because they are so common: (1) Internet “speed tests” (2) domain name system (DNS) queries and responses; (3) probing and scanning. These three classes of active measurements are not exhaustive, but they do capture many cases of active measurement research and practice. We give a brief overview of each in this chapter and offer pointers to more detailed treatment of this material elsewhere.
Types of Active Measurement
Internet speed tests. Perhaps one of the most canonical application performance measurements is the Internet “speed test”, which typically refers as a test of application throughput. Users commonly measure throughput with a client-based “speed test”; a common speed test, for example, is speedtest.net, operated by Ookla. While the detailed designs of these tests may vary, the general principle of these tests is conceptually simple: they typically try to send (or receive) as much data as possible to (or from) some Internet destination as possible and measure the time taken to transfer a particular amount of data over some window. The tests themselves often involve sending a fixed amount of data and measuring the transfer time for that data. Measuring the time it takes for a client to send data to some Internet server corresponds to “upload speed”; measuring the time for a client to receive data from destination corresponds to the “download speed”. Naturally, one critical design choice for an active measurement like a speed test is where to measure to or from; this design consideration is outside the scope of this book, but it is important to note because the quality of the measurements can thus depend on the choice of endpoint to measure.
A common example of an Internet speed test is speedtest.net, but many other organizations operate speed tests, including Measurement Lab’s Network Diagnostic Test (NDT), Fast.com (operated by Netflix), the Federal Communications Commission’s Measuring Broadband America program (which operates a router-based speed test from SamKnows), and so on. The design of Internet speed tests has been varied and contentious over the years; it is the topic of many research papers and outside the scope of this book. We refer the interested reader to related research. Important for the purposes of analysis and machine learning, however, is that these tests often produce two numbers, corresponding to throughput in each direction along a network path, typically measured in megabits per second (or gigabits per second). With the increasing acknowledgement that other metrics are important for understanding network performance (as discussed above), Internet “speed tests” are evolving to include and report on those metrics as well.
A common way to measure latency is using the ping tool, which sends a continuous stream of small packets towards a particular Internet destination, waits for the response, and measures how much time that request-response round trip required. Although ping is a very common tool, it uses a protocol called the Internet control message protocol (ICMP), which can sometimes be blocked by security firewalls and is also sometimes treated completely differently by on-path Internet routers (e.g., prioritized or de-prioritized). Thus, although active measurements are always susceptible to being non-representative of user traffic and experience, ICMP traffic runs this risk even more. As such, an alternative (and common) latency measurement involves sending TCP SYN packets and waiting for the SYN-ACK reply. These transport-level probes allow for sending traffic on ports that are often not filtered by firewalls and more likely to be processed by routers as normal traffic would be. Another commonly used active measurement tool is traceroute, which sends TTL-limited probes to attempt to measure an end-to-end Internet path. As with ping, the nature of how traceroute is implemented introduces various aspects of uncertainty: the probes or the replies may be blocked by middleboxes, and the forward and reverse paths may not be symmetric, leading to various measurement inaccuracies. We refer the reader to related research to understand the limitations of traceroute.
Domain Name System (DNS) queries and responses. The performance of many Internet applications ultimately depends on the performance of the Domain Name System (DNS), the system that maps Internet domain names to IP addresses, among other tasks. Various tools have been developed to measure the performance and characteristics of the DNS, including how DNS relates to application performance (e.g., web page load time), and tests that can detect whether DNS responses have been manipulated (e.g., by an Internet censor or other adversary). With the rise of encrypted DNS protocols (e.g., DNS over HTTPS), there has been increasing attention into the performance of these protocols. As such, new tools have been developed and released to measure both the performance characteristics and behavior of various DNS resolvers.
Internet scans. One of the more established (and general) ways of performing active Internet measurements is to perform a so-called Internet “scan”, which typically involves sending a small amount of traffic (sometimes a single, specially crafted packet) to a single network endpoint and measuring the response. Internet scans could include simple measurements like ping (to measure uptime, or as a simple latency measurement) though commonly they can involve crafting more sophisticated probes that are designed to elicit a particular response. A common type of probe is to send a TCP SYN packet (i.e., the first packet in a TCP connection) to a list of “target” IP addresses and observe how these endpoints respond, in order to perform some kind of conclusion or inference. Such techniques and variants have been performed to conduct Internet-wide characterizations of Internet endpoints (e.g., uptime of network endpoints, operating systems of endpoints). Sophisticated target scans can also be used as active DNS measurements: the Internet contains so-called “open DNS resolvers” that respond to remote active probes, and sending such probes and measuring how resolvers respond can also be useful in characterizing certain aspects of DNS across the Internet. While the most common tools for scanning the Internet are “ping” and “traceroute”, a wide array of scanning tools has been developed, including nmap and more recently zmap.
Applications of Active Measurement
Active measurements can yield information about network endpoints, or about paths between endpoints. As previously mentioned, one common approach to gathering data through active network measurements is through what is called a scan, whereby a single (or small number) of machines on the network send traffic to other network endpoints in an attempt to elicit a response from those endpoints. That response is typically a response that corresponds to the protocol traffic that was sent to the device (e.g., a reply to an ICMP ping, a response to a TCP SYN packet, a response to an HTTP(S) request, a response to a TLS handshake request). Based on those response packets, the measurement device that initiated the active measurement can collect responses. The existence (or lack thereof), format, structure, or content of those responses can then subsequently be used as features in supervised or unsupervised machine learning algorithms for a variety of tasks.
A common application of machine learning to network data gathered from active measurements is fingerprinting. Just about anything in the network can be fingerprinted, or identified—things that can be fingerprinted include network infrastructure (e.g., routers, middleboxes), device types (e.g., laptop, desktop, mobile), operating system, TLS version, and so forth. One classical network fingerprinting tool is called nmap; the tool would scan another network endpoint and, based on the format of reply packets, could then determine with reasonable accuracy the operating system (and OS version) of the endpoint. The conventional version of nmap used a static set of rules to determine the likely operating system using features that were discovered and encoded by hand (e.g., TCP options, congestion control parameters). More recently, research has demonstrated that, given operating system labels and TCP SYN-ACK packets (i.e., responses to the initial part of the TCP three-way handshake), it is possible to train machine learning models that can automatically discover the operating system of a network endpoint, to a much greater degree of accuracy than nmap.
Network measurement has other forms of active measurement that could ultimately be amenable to machine learning, although these areas are somewhat less explored. One particular possible application area is anomaly detection, specifically unsupervised learning techniques to detect unusual, actionable changes in network performance. For example, network operators commonly perform active measurements to measure network characteristics like availability (i.e., uptime), round-trip latency, and so forth. Due to the packet-switched nature of traffic delivery on the Internet, some amount of latency variation and packet loss is normal, and to be expected. On the other hand, more unusual or severe latency aberrations might warrant operator attention. To date, it is less well-understood how to automatically examine longitudinal latency performance measurements and (1) reliably determine when an aberration requires operator attention vs. being part of normal network operations or conditions (e.g., buffering); (2) determine the underlying cause of the latency problem (and, in particular, whether the source of that latency aberration is due to a problem within the ISP network, the user’s home network, an endpoint device, or some other cause).
Passive Measurement¶
In contrast to active measurement, which introduces new traffic into the network to measure the performance of the network, passive measurement monitors existing traffic in the network and infers properties about the network from the measured traffic. Passive measurement has the characteristic (and, in many ways, the advantage) that the resulting data corresponds to actual traffic that is traversing the network (e.g., a user’s actual web browsing or streaming video session) and thus the traffic that is captured may more accurately reflect the properties, behavior, and performance of application performance or user experience.
Types of Passive Measurement
Packet-level monitoring. The most universal form of passive measurement is packet capture, sometimes also called pcap for short. Packet capture is essentially the equivalent of “listening in” on a network conversation, akin to a wiretap of sorts. A packet capture will (as the name suggests), capture all bytes that traverse the network. Common programs that perform packet capture are tcpdump and wireshark. These programs will not only capture the raw bytes as they traverse the network, but they also will parse the bytes into a format that humans (or programs) can read. For example, these programs are equipped with libraries that can parse protocols like Ethernet, TCP, IP, and a variety of application protocols, making it possible to read and understand traffic as it traverses the network.
Packet capture does introduce a few tradeoffs. One disadvantage of pcaps is that they can be quite voluminous, particularly on high-speed links. The volume of packet captures can make it difficult not only to capture all of the packets as they traverse the network, but also to store, transfer, and later process the data. For this reason, packet captures are sometimes truncated—capturing only the packet headers, as opposed to the complete “payload”.
Flow-level monitoring. Other aggregated representations of packet captures are often used to reduce volume, storage, or processing overhead. One common example of aggregation is IPFIX (sometimes more commonly known by Netflow, which is the Cisco-proprietary version of the format). IPFIX reports only aggregate statistics for each flow in the network, where a flow is defined by a unique five-tuple—source and destination IP address, source and destination port, and protocol—as well as a time window of activity (e.g., continuous transfer without an interruption for more than a certain time interval, as well as a maximum time length). For each flow, an IPFIX record contains salient features, such as the start and end time of the flow, the five-tuple of the flow, the number of packets and bytes in the flow, any TCP flags that may have been observed over the duration of the flow, and the router interface on which the traffic was observed. IPFIX has the advantage of being more compact than packet captures, but the format does not represent certain aspects of network traffic that can sometimes be useful for statistical inference and machine learning. For example, IPFIX does not represent individual packet interarrival times, the sizes of individual packets, short-timescale traffic bursts, and so forth.
For many years, packet captures were prohibitively expensive, and operators had to largely make due with sampled packet traces, and even IPFIX records that were based on probabilistic samples of traffic that traversed a router interface (sometimes referred to as “sampled IPFIX” or “sampled NetFlow”). On high-speed links in transit networks, these representations are still common. Yet, increasingly, and especially at the network edge, packet capture at very high rates is now possible. Technologies such as eBPF, PF_RING, and other libraries now make it possible to capture packet traces at speeds of more than 40 Gbps, for example. These new technologies are causing us to reconsider how network traffic might be captured—and represented—for machine learning models. For decades, machine learning models for networking tasks, from performance to security, had to rely in large part on IPFIX-based representations as input. Now, these new capture and monitoring technologies are making it possible to capture raw data at very high rates—and causing us to rethink what the “best” representations might be for a wide array of networking tasks that might rely on machine learning.
Programmatic Interfaces. Ultimately, analyzing packet captures programmatically can require more sophisticated libraries and APIs. While many of these programmatic options are typically restricted to running on general-purpose computing devices (e.g., servers, middleboxes), as opposed to network-specific hardware, software-based options provide significant flexibility in manipulating and analyzing packet capture—including generating features that can be used for machine learning models.
A good place to become familiar with low-level software packet capture libraries, particularly if you are new to the area, is Python’s scapy library; scapy will get you going quickly, but its performance may leave something to be desired if you wish to conduct real-time measurements, parsing, and analysis. Other options have a steeper learning curve; these include eBPF, dpkt, and PF_RING. We have built on these libraries in a tool and accompanying Python library, netml, which we will use to conduct many of the exercises in this book.
Applications of Passive Measurement
There is also an increased desire to measure what is known as quality of experience, or QoE. QoE has several connotations—it can be used to refer to either application quality metrics, for example, video resolution, startup delay, or rebuffering in the case of streaming video. More generally, it can also refer to a user’s general satisfaction level or, rather, quality of experience, when interacting with a particular application; a common metric for this type of QoE is a mean opinion score (MOS). Sometimes, people use the term “application QoE” to differentiate application quality metrics from general user experience.
Tradeoffs: Active vs. Passive Measurement Active measurements may be convenient to implement but have their own drawbacks: (1) they require measuring to a particular network endpoint, which in certain cases (e.g., a speed test, an active measurement of network performance) requires setting up a server on the other end of the measurement; (2) they involve introducing additional traffic into the network, which in some cases may introduce prohibitive network load; (3) because the measurements themselves are synthetic, the measurements themselves may not be representative of what a user actually experiences.
As previously discussed, there is also an increasing desire to measure the quality of specific applications, in particular applications such as web browsing, video streaming, real-time video conferencing, and so forth. One way of assessing the quality of these applications is using active measurements that emulate the behavior of these specific applications. For example, the Federal Communications Commission (FCC) incorporates active measurements for web performance and video streaming performance for specific services into their Measuring Broadband America (MBA) test suite.
There are several challenges with using application-specific measurements to assess application performance. First, application probes must be designed for each specific application, and the probes themselves must mimic the behavior of that application. Accordingly, different applications must have custom probes to accurately measure the performance of the respective application. Furthermore, accurate performance measurement of each application also requires the appropriate measurement infrastructure, such as servers, located in the appropriate locations (e.g., content delivery networks). As a result of these complications, a preferred method for measuring application performance is to passively measure the traffic of the respective applications and infer the application quality. This endeavor turns out to be both a measurement problem and a machine learning problem! We will discuss passive measurement in the next section and applications of machine learning to passively collected network traffic in subsequent sections.
Data Preparation¶
Now that we understand the different forms that network data (and, in particular, network traffic measurements) can take, we turn to understanding some of the tools that enable the capture of network traffic data, as well as the complementary libraries how we can use the data captured using those tools to perform analysis and prediction.
We defer specific discussion of machine learning pipelines to the next chapter, since the application of machine learning models to data presents its own set of challenges. Rather, we will focus on common ways to analyze network traffic using familiar software tools. In this book, we will focus on the use of Python to perform this type of data analysis. Although similar analysis is possible in other frameworks and languages, some of the more cutting-edge tools that we will explore in this book are primarily available through Python APIs, so Python is a good place to start.
Packet Capture¶
A common tool to analyze passive traffic measurements is Wireshark. Wireshark is an application that can be installed on many common operating systems, including Mac, Windows, and Linux. Underlying the Wireshark tool itself is a library called libpcap, which provides an interface between the network interface card and the software applications that read data from packets into memory and process them.
Figure 2 shows an example analysis from Wireshark. Each row in the application represents a single packet, and each column represents a particular field. Clicking on any particular row will yield additional information in the bottom half of the split screen. The information is arranged according to the packet’s “layers”, with the Ethernet information at the top, followed by the IP information, the TCP information, and finally any information that might be contained in the payload. Because much modern Internet traffic is encrypted, most of the information that we will use (and apply) with machine learning examples in this book will come from the header information.
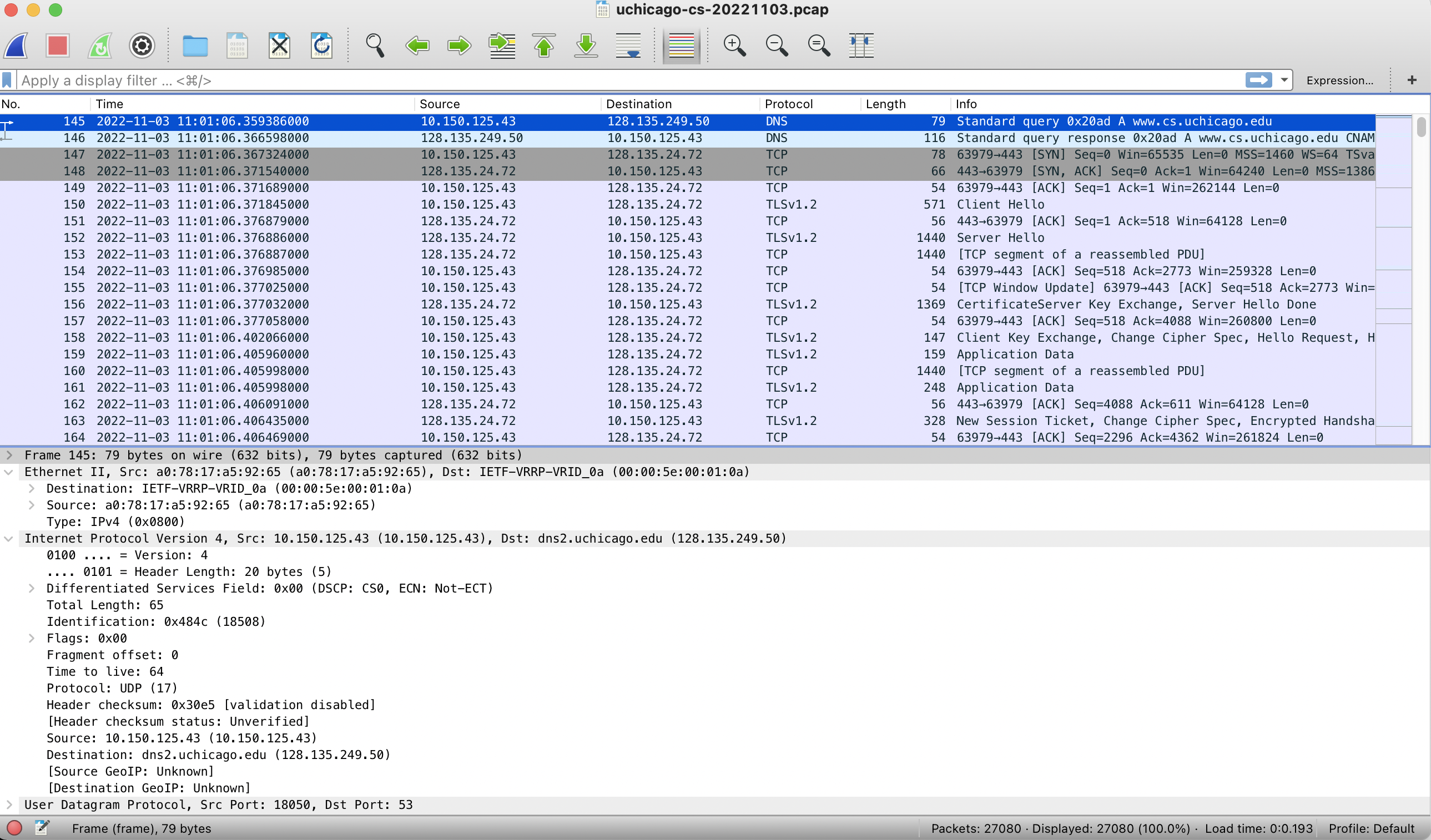
Figure 2. Wireshark capture.¶
Taking a closer look at the fields in each packet, particular information turns out to frequently be useful for a wide variety of machine learning tasks. Relevant features include, for example, the length of each packet and the time that packet was observed. Even before diving into further detail, observe that these two pieces of information alone allow for a wide range of processing options for generating features. For example, packet lengths can be represented individually, as sequences, as summary statistics, as distributions, and so forth. Combined with timing information, it is possible to compute various traffic rates (e.g., packets per second, bytes per second over various time intervals).
Combining these basic statistics with additional information from the packet header makes it possible to generate these features for individual flows: Specifically, individual traffic flows are typically defined by five values across the packet header, sometimes called a 5-tuple: Source and destination IP address, source and destination port, and protocol. Deriving the aforementioned statistics according to packets that belong to the same “flow” (i.e., share a common 5-tuple) also makes it possible to generate (and analyze statistics) across flows, or even groups of related flows. The types of tools that generate this type of flow statistics generally operate on network devices, such as routers and switches. For example, on Cisco routers, the software that is used to produce flow records is commonly referred to as NetFlow. A standard version of this software and format is called IPFIX.
Packets to Data Structures¶
Given network traffic gathered using packet capture tools, the next step is to convert the captured data into a format that can be used for further analysis, including eventual input into machine learning models.
One common format for analyzing data is the Python library Pandas. Pandas provides a data structure called a dataframe, which is a two-dimensional structure that can be used to store data in a tabular format. The columns of the dataframe are analogous to the columns in a spreadsheet, and the rows are analogous to the rows in a spreadsheet. The data in each column is of the same type, and the data in each row is of the same type.
The example below shows an example of a Pandas dataframe that contains information about the number of packets and bytes observed in a particular packet capture. We have used the pcap2pandas function in the netml library to extract various information from the packet capture and store it in a Pandas dataframe.
The function produces a set of columns that are listed in the example below. We have printed out a few rows of the dataframe, with some of these columns extracted, to illustrate basic use of the library.
Converting packet capture data to a Pandas dataframe with netml.
from netml.pparser.parser import PCAP
pcap = PCAP('../examples/notebooks/data/http.pcap')
pcap.pcap2pandas()
pdf = pcap.df
pdf = pdf[['datetime', 'ip_src', 'port_src', 'ip_dst', 'port_dst', 'length']]
pdf.head(10)
'_pcap2pandas()' starts at 2023-04-18 15:55:53
'_pcap2pandas()' ends at 2023-04-18 15:56:00 and takes 0.1169 mins.
| datetime | ip_src | port_src | ip_dst | port_dst | length | |
|---|---|---|---|---|---|---|
| 0 | 2022-09-29 20:24:42 | 192.168.1.58 | 57256 | 35.186.224.43 | 443 | 109 |
| 1 | 2022-09-29 20:24:42 | 35.186.224.43 | 443 | 192.168.1.58 | 57256 | 66 |
| 2 | 2022-09-29 20:24:42 | 35.186.224.43 | 443 | 192.168.1.58 | 57256 | 106 |
| 3 | 2022-09-29 20:24:42 | 192.168.1.58 | 57256 | 35.186.224.43 | 443 | 66 |
| 4 | 2022-09-29 20:24:42 | 192.168.1.58 | 60463 | 172.64.154.162 | 443 | 60 |
| 5 | 2022-09-29 20:24:42 | 172.64.154.162 | 443 | 192.168.1.58 | 60463 | 60 |
| 6 | 2022-09-29 20:24:42 | 54.201.14.11 | 443 | 192.168.1.42 | 50325 | 66 |
| 7 | 2022-09-29 20:24:42 | 192.168.1.42 | 50325 | 54.201.14.11 | 443 | 66 |
| 8 | 2022-09-29 20:24:42 | 140.82.112.26 | 443 | 192.168.1.58 | 59966 | 92 |
| 9 | 2022-09-29 20:24:42 | 192.168.1.58 | 60848 | 142.251.32.4 | 443 | 78 |
Data Structures to Features¶
After data acquisition, the next step is preparing the data for input to train models. Data preparation involves organizing the data into observations, or examples; generating features and (in the case of supervised learning) a label for each observation; and preparing the dataset by dividing the data into training and test sets (typically with an additional sub-division of the training set to tune model parameters).
Many supervised machine learning problems represent the training examples as a two-dimensional matrix. Each row of the matrix contains a single example. Each column of the matrix corresponds to a single feature or attribute. This means that each example (row) is a vector of features (columns). This definition is quite flexible and works for many networks problems at different scales. For example, each example might correspond to an IPFIX flow record, with features corresponding to the number of packets in the flow, the start and end times of the flow, the source and destination IP addresses, etc. In a different problem, each example might correspond to a single user, with features representing average throughput and latency to their home router in 1-hour intervals. This flexibility is a boon, because it allows developers of machine learning algorithms to work with a consistent mathematical formulation—a matrix (or table) of examples and features. In this book, we will generally refer to a matrix of training examples as X. Sometimes in code examples we will also use features to refer to the matrix of training examples.
Representations of network traffic that are most effective for prediction and inference problems in networking detection are typically {em a priori} unclear. Representation choices typically involve various statistics concerning traffic volumes, packet sampling rates, and aggregation intervals. Yet, which of these transformations retain predictive information is typically initially unknown. One example challenge is choosing the granularity on which to aggregate a feature: For instance, if we decide to measure and represent the number of packets per second as a feature, then changes in traffic patterns at the millisecond level might go undetected; on the other hand, recording at this granularity creates higher dimensional observations introducing high-dimensional data that creates challenges with both scale and accuracy. (The so-called curse of dimensionality in machine learning is the observed fact that the higher the dimension of the input, the harder it is to achieve good accuracy; in particular, we might then require an amount of training data exponential as a function of dimension.)
In the context of networking, a example might be an individual packet, an entire traffic flow (with associated summary statistics), information about a connection or transaction, and so forth. In the last chapter, we explored the process by which which raw packet traces can be performed into certain features, such as flows. In this chapter, we will see how to take this process a step further, by transforming the data into a labeled dataset for input to a machine learning model—and how to ultimately train and evaluate the resulting model using this data.
The process of feature extraction from raw network traffic affects the accuracy of a variety of models. There are many possible ways to represent raw traffic traces (i.e., packets) as inputs. The data itself can be aggregated on various time windows, elided, transformed into different bases, sampled, and so forth. We focus on representations of network traffic data that do not incorporate semantics from the header itself, such as IP addresses, port numbers, sequence numbers, or other specific values in the packet headers themselves. Representations that are agnostic to specific values in the headers ensures that the resulting models are trained to recognize novel behavior regardless of the {em specific} source, destination, application, or location in the network. In contrast to past work in this area, which has typically focused on a single problem in novelty detection using a single dataset and a chosen procedure, our focus is on studying the applicability of representation, we aim for {em generality} and reproducibility of results across a range of problems, studying the applicability of different representations across a range of problems.
netml is a network anomaly detection tool and library written in Python. It consists of two sub-modules: (1) a pcap parser that produces flows using Scapy/dpkt and (2) a novelty detection module that applies the novelty detection algorithms. The library takes network packet traces as input, transforms them into various data representations, and can be incorporated as a Python library or invoked directly from the command line.
The netml software package includes a Python library, the netml command-line utility, and the rest of the code in support of various utilities (e.g., testing). netml is a useful tool for converting network traffic captures to features that can be used for various network analysis tasks. It has been designed, implemented, and released as an open-source tool to help researchers and practitioners in the field of network security.
Below is an example of the netml library’s capability for converting passive traffic measurements to 12 different features for each traffic flow. The example below shows the features associated with the first three flows in the packet trace. Those features are: flow duration, number of packets sent per second, number of bytes per second, and various statistics on packet sizes within each flow: mean, standard deviation, inter-quartile range, minimum, and maximum, the total number of packets, and total number of bytes. The netml library supports a variety of different feature extraction methods.
Extracting features from a packet capture with netml.
from netml.pparser.parser import PCAP
from netml.utils.tool import load_data
import pandas as pd
pcap = PCAP(
'../examples/notebooks/data/http.pcap',
flow_ptks_thres=2,
random_state=42,
verbose=10,
)
pcap.pcap2flows()
# Extract inter-arrival time features
pcap.flow2features('STATS', fft=False, header=False)
features = pd.DataFrame(pcap.features)
features.head(3)
'_pcap2flows()' starts at 2023-04-18 15:56:08
pcap_file: ../examples/notebooks/data/http.pcap
ith_packets: 0
ith_packets: 10000
ith_packets: 20000
len(flows): 593
total number of flows: 593. Num of flows < 2 pkts: 300, and >=2 pkts: 293 without timeout splitting.
kept flows: 293. Each of them has at least 2 pkts after timeout splitting.
flow_durations.shape: (293, 1)
col_0
count 293.000
mean 11.629
std 15.820
min 0.000
25% 0.076
50% 0.455
75% 20.097
max 46.235
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 293 entries, 0 to 292
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 col_0 293 non-null float64
dtypes: float64(1)
memory usage: 2.4 KB
None
0th_flow: len(pkts): 4
After splitting flows, the number of subflows: 291 and each of them has at least 2 packets.
'_pcap2flows()' ends at 2023-04-18 15:56:13 and takes 0.086 mins.
'_flow2features()' starts at 2023-04-18 15:56:13
True
'_flow2features()' ends at 2023-04-18 15:56:13 and takes 0.0046 mins.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 30.076 | 0.133 | 11.637 | 87.500 | 21.500 | 66.000 | 87.500 | 109.000 | 66.000 | 109.000 | 4.000 | 350.000 |
| 1 | 30.060 | 0.133 | 11.444 | 86.000 | 20.000 | 66.000 | 86.000 | 106.000 | 66.000 | 106.000 | 4.000 | 344.000 |
| 2 | 40.960 | 0.122 | 8.057 | 66.000 | 0.000 | 66.000 | 66.000 | 66.000 | 66.000 | 66.000 | 5.000 | 330.000 |